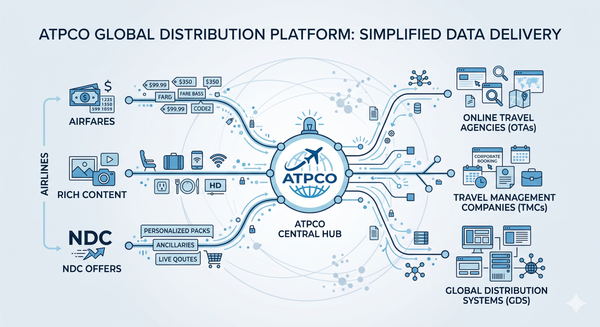
[번역] 호텔을 위한 'AI SEO'가 약장수인 이유
hotelport.com의 CEO인 Fred Bean의 Phocuswire 기고문 "The architecture of truth: Why ‘AI SEO’ for hotels is snake oil"이 매우 인상적이어서 전문을 번역하여 공유합니다. 저자는 각종 GEO, AEO 마케팅이 일종의 패닉 바잉 상황이라고 진단하고 있습니다. snake oil은 옛날 미국의 가짜 만병통치약 이라는군요.

![[번역] 호텔을 위한 'AI SEO'가 약장수인 이유](/content/images/size/w1200/2026/06/Gemini_Generated_Image_l957pvl957pvl957.png)
원문 : The architecture of truth: Why ‘AI SEO’ for hotels is snake oil
현재 호스피탈리티 마케팅 업계는 이른바 '패닉 바잉(Panic buying)'이라는 조용한 전염병을 앓고 있습니다. 인공지능이 소비자의 여행 계획 방식을 어떻게 뒤흔들지 극심한 불안감에 사로잡힌 호텔 소유주와 브랜드 경영진들은 '생성형 엔진 최적화(GEO : AI 모델의 추천을 유도하는 최적화 기술)'나 'AI 검색 엔진 최적화(AI SEO : AI 검색 환경에 맞춘 웹사이트 최적화)' 패키지를 판매하는 디지털 대행사에 엄청난 액수의 수표를 발행하고 있습니다. 이러한 상품들은 특수한 마크다운 코딩(Markdown coding : 웹상에서 텍스트를 서식화하는 가벼운 마크업 언어), 숨겨진 사이트 파일, 혹은 인위적으로 조작된 온라인 포럼의 언급 등을 활용하여 ChatGPT, Perplexity, 구글의 AI 모드 같은 추천 엔진에 자사 호텔을 강제로 밀어 넣을 수 있다고 장담합니다.
그러나 이는 비용만 낭비하는 주의 분산 책에 불과합니다.
구글은 공식 서치 센트럴(Search Central : 구글이 웹마스터와 마케터를 위해 제공하는 공식 검색 가이드) 문서인 "Google 검색의 생성형 AI 기능에 맞게 웹사이트 최적화하기
"를 통해 이러한 인위적인 전술들을 체계적으로 정면 반박하고 있습니다. 기술적인 실체는 명백합니다. 생성형 AI 기능은 별도의 격리된 아키텍처 위에서 구동되거나 비밀 데이터베이스를 조회하지 않습니다. 오히려 기존의 핵심 유기적 검색 순위 및 품질 시스템(Core organic search ranking and quality systems : 광고가 아닌 자연 검색 결과의 순위를 매기는 구글의 핵심 알고리즘)과 엄격하게 연속 선상에 놓여 있습니다.

구글의 검색 기술 가이드는 참고할 부분이 꽤 많습니다.
AI 여행 컨시어지의 추천을 받기 위해 필요한 것은 인위적인 최적화 꼼수가 아닙니다. 필요한 것은 다름 아닌 철저하고 흔들림 없는 '데이터 거버넌스(Data governance : 데이터의 정확성, 일관성, 보안을 전사적으로 관리하는 통제 체계)'입니다. 그 이유를 이해하려면 호텔 경영진들은 겉으로 보이는 사용자 인터페이스를 넘어, 대화형 검색을 이끄는 두 가지 핵심 배경 기술을 정확히 꿰뚫어 보아야 합니다.
첫째, 검색 증강 생성(RAG : 외부 데이터를 조회하여 AI의 답변 정확도를 높이는 기술)입니다. AI 모델이 체크인 시간, 객실 수, 반려견 몸무게 제한 등을 제멋대로 지어내는 환각 현상(Hallucination : AI가 그럴듯하지만 완전히 거짓된 정보를 생성하는 오류)을 방지하기 위해, 전체 AI 생태계는 RAG 기술(업계에서는 흔히 '그라운딩(Grounding : AI 답변을 실제 사실 데이터에 결합하는 프로세스)'이라 지칭함)에 전적으로 의존합니다. 구글의 프레임워크에 따르면, 모델은 핵심 검색 인덱스를 실시간으로 크롤링(Crawl )하여 검증된 최신의 정보를 추출합니다. 그 후 추출된 현실 세계의 데이터를 검토 및 분석하여 자연스러운 언어로 요약본을 생성한 뒤, 원본 웹 소스로 바로 연결되는 클릭 가능한 출처 인용 링크(Citation links : 정보의 출처를 밝히고 연결해 주는 하이퍼링크)를 눈에 띄게 첨부합니다.
둘째, 검색어 분산 확장 처리(Query fan-out : 하나의 복잡한 질문을 여러 하위 검색으로 쪼개어 동시에 처리하는 방식)입니다. 이제 여행객들은 "마이애미 비치 호텔"과 같이 단편적인 키워드로 검색하지 않습니다. 대신 다중 의도가 포함된 대화형 문장을 입력합니다. 예를 들어 “마이애미 비치에 있는 호텔 중에서 50파운드 미만의 반려견 동반이 가능하고, 원격 근무를 위한 빠른 와이파이가 제공되며, 전기차 충전소가 있는 조용한 부티크 호텔을 찾아줘”라는 프롬프트를 입력하면, 구글의 AI는 즉시 '검색어 분산 확장 처리(Query fan-out)'를 실행합니다.
이 단 하나의 프롬프트는 즉각적으로 해체되어 반려견 정책, 전기차 충전 인프라, 그리고 웹 전반에 걸친 투숙객 리뷰 감성(Review sentiments : 이용 후기에 나타난 소비자들의 긍정적 또는 부정적 감정 성향)을 다각도로 평가하는 독립적이고 동시적인 백그라운드 조회를 수행합니다. AI는 이처럼 웹상에 존재하는 개방된 컨센서스(Consensus : 다양한 소스에서 공통으로 확인되는 정보의 일치성 및 합의)를 종합합니다. 만약 특정 호텔의 데이터가 AI가 추적하는 모든 플랫폼에서 이 분산 확장 배열의 단 하나의 조건도 빠짐없이 완벽히 일치한다면, 최종 추천 리스트에 취합됩니다. 그러나 단 하나의 데이터라도 누락되었거나, 서로 모순되거나, 검증되지 않는다면 AI 엔진은 해당 정보에 대한 신뢰도를 잃고 최종 출력 결과에서 해당 호텔을 즉시 배제합니다.
구글이 밝힌 가짜 기술 매트릭스 (Google’s myth-busting matrix)
구글의 공식 문서는 AI 검색 생성에 아무런 영향을 미치지 못하는 요소들이 무엇인지 다음과 같이 명확한 가이드라인을 제시하고 있습니다.
- LLMS.txt 파일 및 마크다운 : 이들은 그저 일반 텍스트 파일과 동일하게 취급될 뿐이며, 우선적인 인덱싱(Indexing : 검색 엔진이 웹 페이지를 분석하고 데이터베이스에 등록하는 과정)이나 지름길을 제공하지 않습니다. AI 엔진은 특수한 텍스트 파일이 아니라, 웹상에 실시간으로 존재하는 기업의 공개된 배포 흔적(Distribution footprints : 다양한 플랫폼과 소스에 남겨진 브랜드 데이터의 흔적)을 직접 확인합니다.
- 콘텐츠 '청킹(Chunking : 대량의 텍스트 정보를 인위적으로 작은 단위로 쪼개는 작업)' : 콘텐츠를 미시적인 단락 단위로 잘게 파편화할 필요가 전혀 없습니다. 고도로 발전한 거대언어모델(LLM)은 여러 주제가 섞인 페이지를 자연스럽게 이해하며 필요한 특정 구절을 스스로 찾아냅니다.
- 인위적인 언급 조작 : 검색 노출 순위나 포럼 게시글을 인위적으로 구매하는 행위는 구글의 스팸 방지 알고리즘(Anti-spam algorithms : 부정한 방법으로 검색 순위를 조작하는 행위를 걸러내는 시스템)을 자극할 뿐입니다. 구글의 핵심 품질 시스템은 조작된 마케팅 행위와 실제 투숙객의 진정성 있는 여론을 손쉽게 구별해 냅니다.
- AI 전용 문체 재작성 : 롱테일 키워드(Long-tail keyword : 구체적이고 길게 조합된 틈새 검색어) 변형을 모두 잡아내기 위해 정보를 인위적으로 재진술하는 것은 무의미합니다. 자연어 모델은 동의어, 문맥, 그리고 의미론적 의도(Semantic intent : 단어의 사전적 정의를 넘어 사용자가 진짜 의도한 맥락과 의미)를 직관적으로 이해하기 때문입니다.
더 나아가 구글은 다른 웹사이트의 정보를 단순히 요약하거나 복제한 짜깁기성 '범용형 콘텐츠(Commodity content : 차별성 없는 저부가가치 정보)'는 RAG 파이프라인(RAG pipelines : 검색 증강 생성을 수행하는 데이터 처리 경로)에서 완전히 외면받을 것이라고 강력히 경고합니다. AI는 독창적인 관점, 직접 겪은 운영 사례 연구, 원본 사진, 그리고 인터넷 그 어디에서도 합성해 낼 수 없는 극도로 지역화된 전문가의 통찰력이 담긴 '비범용형 콘텐츠(Non-commodity content : 독창적이고 대체 불가능한 고부가가치 정보)'를 압도적으로 우대합니다.
3단계 거버넌스의 전사적 집행
이러한 근본적인 아키텍처는 현대 호텔 브랜드들이 마주한 진짜 취약점이 다름 아닌 극심한 '채널 파편화(Channel fragmentation : 호텔의 정보가 통제 없이 수많은 예약 사이트와 플랫폼으로 흩어져 분산되는 현상)'에 있음을 적나라하게 드러냅니다. 현재 호텔의 정보는 수십 개의 제3자 플랫폼, OTA, GDS, 지도 서비스 공급자, 그리고 리뷰 플랫폼 전반에 무분별하게 흩어져 있습니다. 이 생태계에서 살아남기 위해 호스피탈리티 브랜드들은 단순히 특정 채널의 오류를 방어적으로 해결하는 땜질식 처방에서 벗어나, 다음의 3가지 핵심 단계에서 완벽한 브랜드 거버넌스를 구축해야 합니다.
- 1단계 : 발견 (Discovery) 단계. 이 초기 단계에서 여행객들은 복잡한 라이프스타일 중심의 기준을 바탕으로 대화형 모델을 활용해 선택지를 탐색합니다. 그러나 채널 파편화로 인해 웹 전반에서 편의시설 태그가 불일치하거나, 텍스트 필드가 깨지거나, 속성 값이 누락되는 문제가 발생합니다. AI 엔진이 동일한 호텔에 대해 서로 충돌하는 매개변수를 발견하면, 해당 데이터에 대한 신뢰도 점수(Confidence score : AI가 특정 정보의 정확성을 확신하는 수치적 정도)를 낮추고 그 호텔을 추천에서 제외합니다. 따라서 AI 시대의 절대적 과제는 명확합니다. 다중 채널 전체에서 완벽한 데이터 동질성(Data parity : 여러 플랫폼에 흩어진 데이터가 완전히 일치하는 상태)을 달성해야 하며, 특히 올바르게 작성된 구글 비즈니스 프로필(Google Business Profile : 구글 검색 및 지도에 표시되는 기업의 공식 정보 관리 도구)과 같은 구조화된 데이터 저장소를 최우선으로 관리해야 합니다.
- 2단계 : 결정 (Decision) 단계. 사용자가 검증되지 않은 객실 크기, 불명확한 체크인 절차, 혹은 확인되지 않은 주차장 제한 조건 등 모호한 데이터 레이어(Data layers : 정보를 구성하는 세부 데이터의 계층)를 마주하여 마찰을 겪을 때 예약 망설임 현상이 일어납니다. 현대의 AI 엔진은 정형화되지 않은 투숙객의 가공되지 않은 리뷰 텍스트(Unstructured guest review text : 평점처럼 수치화되지 않고 자유롭게 작성된 고객의 후기)까지 샅샅이 긁어모아(Scrape) 정밀한 비교 질문에 답변하기 때문에, 수익 관리자 및 브랜드 책임자들은 자사의 핵심 기준 데이터(System-of-record data : 기업 내에서 가장 신뢰할 수 있는 단 하나의 원천 기준 데이터)를 극도로 정밀하게 관리해야 하며, 다중 플랫폼의 리뷰 감성을 철저히 추적하여 LLM이 학습하는 내용과 실제 운영 현황을 완벽하게 일치시켜야 합니다.
- 3단계 : 도착 (Arrival) 단계. 투숙객의 여정은 예약 시점에서 끝나지 않습니다. 위치 메타데이터(Metadata : 데이터를 설명하는 하위 속성 데이터)가 불일치하거나, 출입구 위치가 잘못 지정되었거나, 지도 좌표가 어긋나 있으면 고객은 도착하자마자 큰 불편을 겪게 됩니다. 이는 결국 부정적인 리뷰로 이어지며, 이 부정적인 리뷰는 다음 여행객을 위한 '발견 단계'의 데이터 레이어를 다시 오염시키는 악순환을 낳습니다. 따라서 모빌리티 시스템, 지도 API, 그리고 글로벌 내비게이션 좌표는 호텔의 실제 물리적 배치와 정확히 일치하도록 엄격하게 통제되어야 합니다.
진실의 인프라로 전환
대화형이자 에이전트 중심의 AI 검색(Conversational, agentic AI search : 사용자의 복잡한 의도를 스스로 이해하고 자율적으로 판단하여 최적의 결과를 도출하는 인공지능 검색 환경) 시대에 안일하게 대처했을 때 치르는 전략적 대가는 AI 결과 페이지에서의 '체계적인 소멸'입니다. 일시적이고 단편적인 콘텐츠 업데이트에 의존하거나 임시방편적인 최적화 편법을 구매하는 것으로는 구조적인 데이터 문제를 절대 해결할 수 없습니다.
호스피탈리티 업계의 경영진들은 근시안적인 채널 업데이트 수준을 넘어서서, 영구적이고 구조적인 브랜드 거버넌스를 확보해야 합니다. 호텔이 자신의 근간이 되는 기저 데이터(Underlying data)에 대한 절대적인 통제권을 쥐고 공개된 웹 전반에서 검증된 합의를 강제해 낼 때, 비로소 시장에서의 브랜드 서사(Market narrative)를 완전히 지배할 수 있습니다. 기억하십시오, 거버넌스가 최적화보다 먼저입니다.
본 글의 저자는 호스피탈리티 업계의 콘텐츠 유통 기업인 HotelPORT.com의 CEO인 Fred Bean입니다.